
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 메소드
- Python
- Method
- 프로그래밍
- 코딩
- String
- Database
- 문자열
- It
- java
- JavaScript
- frontend
- function
- 웹
- jsp
- oracle
- 프론트엔드
- PL/SQL
- 데이터베이스
- 자바
- 오라클
- Servlet
- 자바스크립트
- HTML
- 파이썬
- Programming
- 함수
- web
- 서블릿
- SQL
- Today
- Total
Untitled_Blue
[JAVA] 컬렉션 프레임워크 2 - Set 본문
안녕하세요. 이번 글은 자바 컬렉션 프레임워크 중 Set에 대한 설명입니다.
- Set이란?
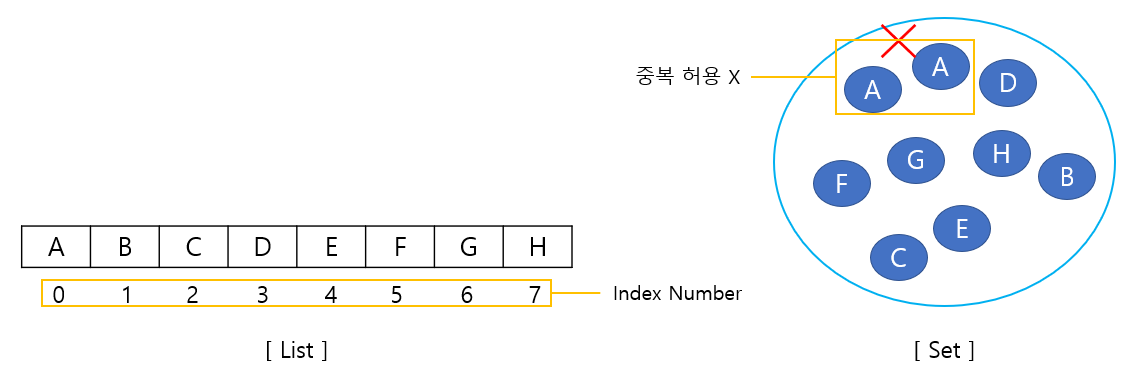
Set이란 기존 List와 다르게 인덱스 정보가 없는 컬렉션을 의미하며 인덱스가 없는 만큼 데이터 자체를 데이터를 구분하는 것이 특징이다. 그만큼 동일한 데이터의 저장이 허용되지 않는다. Set의 종류로는 HashSet, TreeSet, LinkedSet이 있다.
- Set 관련 공통 메서드
| 메서드 | 설명 |
| .add(E element) | 매개변수의 원소를 컬렉션에 추가 |
| .addAll(Collection<E> e) | 컬렉션에 다른 컬렉션 전체 추가 삽입 |
| .remove(Object o) | 컬렉션 내 지정 요소 삭제 |
| .clear() | 컬렉션 내 데이터 전체 삭제 |
| .isEmpty() | 컬렉션 객체가 비어있는지 확인 |
| .contains(Object o) | 매개변수 요소가 컬렉션에 있는지에 대한 여부 확인 |
| .size() | 컬렉션의 데이터 개수 확인 |
| .iterator() - hasnext() | 다음 요소 뒤에 읽어올 값이 있는지를 확인 |
| .iterator() - next() | 다음 요소 호출 |
해당 메서드를 하나씩 구현하면서 실습할 예정인데, 대표적으로 HashSet()를 활용해서 확인해볼 것이다.
- .add(), .size()
package classes;
import java.util.HashSet;
import java.util.Set;
public class CFrame_Set {
public static void main(String[] args) {
Set<String> set = new HashSet<String>();
set.add("A");
set.add("B");
set.add("C");
set.add("D");
set.add("E");
set.add("F");
System.out.println(set.size()); // 6
Set<String> set02 = new HashSet<String>();
set02.addAll(set);
set02.add("G");
set02.add("H");
System.out.println(set02.size()); // 8
set02.add("A"); // 중복값이 존재하므로 추가되지 않음.
System.out.println(set02.size()); // 8 -> 추가되지 않았음을 확인가능
}
}다음 소스코드와 같이 .add(Object o)를 통해 객체를 생성할 때 설정해둔 제너릭에 맞게 요소를 추가할 수 있음과 .size()를 통해 객체 내 데이터의 개수를 정상적으로 확인할 수 있다. 또한 .setAll(Collection<E> c)를 통해 기존에 존재하는 컬렉션 내 데이터를 자신의 객체로 복사함으로써 가져올 수 있음 또한 확인할 수 있다. 무엇보다도 기존에 있던 값을 다시 추가하려고 할 때 추가 전후로 데이터의 개수가 달라지지 않음을 볼 수 있는데 이를 통해 Set이 중복성을 허용하지 않는다는 점을 확인할 수 있다.
- hasNext(), next()
package classes;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class CFrame_Set {
public static void main(String[] args) {
Set<String> set = new HashSet<String>();
set.add("A");
set.add("B");
set.add("C");
set.add("D");
set.add("E");
set.add("F");
set.add("G");
set.add("H");
Iterator<String> iter = set.iterator();
while (iter.hasNext()) {
System.out.print(iter.next() + " "); // A B C D E F G H
}
System.out.println();
System.out.println(set.toString()); // [A, B, C, D, E, F, G, H]
}
}다음 소스코드를 통해 hasNext()와 next()를 통해 객체 내 데이터를 출력할 수 있음을 알 수 있다. 이때 반복자를 반환하는 역할을 하는 iterator()라는 메서드가 나왔는데 이 메서드는 컬렉션에 대한 반복자로서 객체 내부의 데이터를 하나씩 처리할 때 사용한다. 열거형의 모습을 하고 있는데 이를 컬렉션계의 enum이라고 봐도 무방하다고 볼 수 있다.
hasNext()를 반복문 안에 넣어서 다음 요소에 값이 없을 때까지 반복하면서 .next() 메서드를 통해 객체 안에 있는 데이터를 하나씩 반환하는 과정을 거침으로써 객체 내 데이터를 모두 확인할 수 있다. toString()으로도 볼 수 있다. 하나하나 대조하는 방식의 로직을 구현할 때는 .hasNext()와 .next()를 사용하는 것을 추천한다.
- .remove(), .clear(), .isEmpty()
package classes;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class CFrame_Set {
public static void main(String[] args) {
Set<String> set = new HashSet<String>();
set.add("A");
set.add("B");
set.add("C");
set.add("D");
set.add("E");
set.add("F");
set.add("G");
set.add("H");
System.out.println(set.toString()); // [A, B, C, D, E, F, G, H]
set.remove("D");
System.out.println(set.toString()); // [A, B, C, E, F, G, H]
set.remove("F");
System.out.println(set.toString()); // [A, B, C, E, G, H]
System.out.println(set.isEmpty()); // false
set.clear();
System.out.println(set.toString()); // []
System.out.println(set.size() + " " + set.isEmpty()); // 0 true
}
}다음 소스코드를 통해 .remove(Object o)를 통해 매개변수를 활용해서 특정 데이터를 찾아서 삭제할 수 있음을 먼저 확인할 수 있다. 또한 isEmpty()를 통해 객체 내 공간이 비었는지에 대한 여부를 확인할 수 있으며 .clear()를 통해 객체 내 데이터를 모두 초기화할 수 있음을 확인가능하다. 이는 .clear() 전후로 .isEmpty()를 사용함으로써 검증 가능하다.
- .contains()
package classes;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class CFrame_Set {
public static void main(String[] args) {
Set<String> set = new HashSet<String>();
set.add("A");
set.add("B");
set.add("C");
set.add("D");
set.add("E");
set.add("F");
set.add("G");
set.add("H");
System.out.println(set.contains("B")); // true
System.out.println(set.contains("K")); // false
}
}다음 소스코드를 통해 .contains(Object o) 메서드를 통해 객체 내 특정 값이 있는지에 대한 여부를 확인할 수 있다. 이는 데이터를 검색하는 기능이라고 볼 수 있으며 이를 실제로 로직을 구현할 때 활용 가능하다.
- HashSet<E>의 자식 클래스는 LinkedHashSet<E>

LinkedHashSet은 HashSet에서 전체적으로 데이터 간의 상호유기적으로 서로의 정보가 연결된다는 점이 추가된 클래스다. 서로의 정보를 양방향으로 연결함으로써 기존 HashSet에서는 없었던 입출력의 순서를 사용할 수 있다는 점에서 차이점이 존재한다. 그러나 Set 인터페이스의 고유적 특성이 존재하는 만큼 중간에 데이터를 추가하거나 순서를 기반으로 특정 값을 추출해오는 것은 불가능하다.
- 트리구조처럼 상하관계가 존재하는 TreeSet<E>
TreeSet 클래스는 나무를 바탕으로 하는 클래스이며 자료구조에서 트리구조처럼 상하관계가 존재하는 클래스를 의미한다. 여기서도 Set 인터페이스 특정상 중복성이 허용되지 않는다.
| 메서드 | 설명 |
| .first(), .last() | 원소 중 가장 작은 값 또는 큰 값 반환 |
| .lower(E element), .higher(E element) | 원소 중 입력된 요소보다 작은 또는 큰 값 반환 |
| .floor(E element), .ceiling(E element) | 매개변수 요소보다 같어나 작은/큰 수 반환 |
| .pollFirst(), .pollLast() | 원소들 중 가장 작은 또는 큰 요소 추출 |
| .headSet(E toElement) | 매개변수 요소 미만인 모든 원소의 집합 반환 |
| .headSet(E toElement, boolean inclusive) | 매개변수 요소 이하인 모든 원소의 집합 반환 (true : 이하, false : 미만) |
| .tailSet(E toElement) | 매개변수 요소 이상인 모든 원소의 집합 반환 |
| .tailSet(E toElement, boolean inclusive) | 매개변수 요소 초과인 모든 원소의 집합 반환 (true: 초과, false : 이상) |
| .subSet(E fromElement, boolean inclusive) | fromElement 이상 toElement 미만인 모든 원소의 집합 반환 |
| .subSet(E fromElement, boolean frominclusive, E toElement, boolean toinclusive) | fromElement 초과/이상 toElement 미만/이하인 모든 원소의 집합 반환 |
| .descendingSet() | 현재 정렬 기준을 반대로 반환 |
상단의 표는 TreeSet<E>의 메서드를 정리한 목록이다. 트리구조를 기반으로 하는 만큼 크기를 기준으로 하는 메서드가 많다는 점을 확인할 수 있다.
package classes;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeSet;
public class CFrame_Set {
public static void main(String[] args) {
TreeSet<Integer> set = new TreeSet<Integer>();
set.add(1);
set.add(2);
set.add(3);
set.add(4);
set.add(5);
set.add(6);
set.add(7);
set.add(8);
System.out.println(set.first()); // 1
System.out.println(set.last()); // 8
System.out.println(set.lower(5)); // 4
System.out.println(set.higher(5)); // 6
System.out.println(set.floor(3)); // 3
System.out.println(set.ceiling(3)); // 3
System.out.println(set.pollFirst()); // 1
System.out.println(set.pollLast()); // 8
System.out.println(set.headSet(4)); // [2, 3]
System.out.println(set.headSet(4, true)); // [2, 3, 4]
System.out.println(set.headSet(4, false)); // [2, 3]
System.out.println(set.tailSet(5)); // [5, 6, 7]
System.out.println(set.tailSet(5, true)); // [5, 6, 7]
System.out.println(set.tailSet(5, false)); // [6, 7]
System.out.println(set.subSet(1, 6)); // [2, 3, 4, 5]
System.out.println(set.subSet(1, true, 6, false)); // [2, 3, 4, 5]
System.out.println(set.descendingSet()); // [7, 6, 5, 4, 3, 2]
}
}상단의 소스코드는 TreeSet<E>과 관련된 핵심적인 메서드를 실습한 결과이다. 트리구조를 기반으로 하면서 상하관계가 존재하는 만큼 값의 크기를 대조 내지 확인하면서 반환 및 추출하는 메서드가 많음을 확인할 수 있다.
다음 글은 컬렉션 프레임워크 종류 중 하나인 Map에 대한 설명입니다. 감사합니다.
'Programming Language > JAVA' 카테고리의 다른 글
| [JAVA] 제네릭 (Generic) (0) | 2023.06.07 |
|---|---|
| [JAVA] 컬렉션 프레임워크 3 - Map (0) | 2023.06.05 |
| [JAVA] 컬렉션 프레임워크 1 - List, Stack (0) | 2023.06.04 |
| [JAVA] 예외 처리 (0) | 2023.05.25 |
| [JAVA] 인터페이스 (0) | 2023.05.21 |



