
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 함수
- 웹
- 메소드
- Database
- 파이썬
- It
- HTML
- java
- 문자열
- jsp
- Method
- frontend
- 프론트엔드
- String
- 오라클
- Python
- function
- oracle
- 코딩
- 자바
- 프로그래밍
- SQL
- Programming
- 자바스크립트
- JavaScript
- web
- Servlet
- 서블릿
- 데이터베이스
- PL/SQL
- Today
- Total
Untitled_Blue
[Python] 파이썬의 시작, 자료형과 print() 본문
안녕하세요. 이번 글은 파이썬의 자료형과 출력문인 print()에 대한 설명입니다.
필자는 Python 3.12와 JetBrains사의 PyCharm 2023.05 IDE를 사용하고 있음을 밝힙니다.
- print() : 콘솔에서 내용을 출력하기 위한 일종의 문법
print("Welcom to Python !")
#print("Welcom to JAVA !")
다음과 같이 print()를 통해 원하는 문자를 출력할 수 있음을 확인할 수 있으며 다른 언어에 비해 출력하기 위한 문법이 상대적으로 간결하다는 점 또한 확인할 수 있다. 또한 # 이라는 특수문자를 활용해서 주석처리할 수 있다는 점도 확인가능하다.
- 자료형 (Data Type)

자료형이란 데이터를 저장하는 일종의 저장공간을 의미한다. 파이썬은 동적 언어인만큼 다른 정적 언어인 Java와 C# 등과 다르게 변수를 선언할 때 별도의 자료형을 지정하지 않는다. 여기서 동적 언어란 자료형이 동적으로 변하는 언어를 의미하며 정적 언어는 반대로 자료형이 동적이 정하지 않는 만큼 사전에 자료형을 선언해줘야 한다. type() 함수를 사용하면 변수의 자료형을 확인할 수 있다.
a = 1
b = 2
c = 3.5
d = 4.5
e = 12j
print(a)
print(b)
print(a + b)
print('===========')
print(c)
print(d)
print(c + d)
print('===========')
print(e)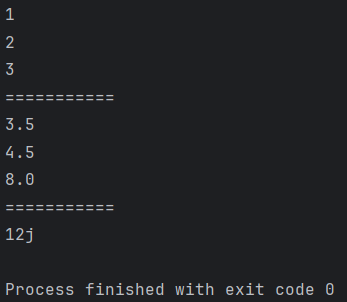
다음과 같이 별도로 자료형을 선언하지 않아도 변수에 값을 넣기만 해도 정상적으로 컴파일되서 실행되는 점을 확인할 수 있다. 여기서 type(변수명)을 사용하면 해당 변수의 자료형이 무엇인지를 확인할 수 있다. 또한 파이썬은 복소수를 위한 타입이 따로 존재하는데 이를 complex라고 한다.
a = 'Hello. Pyhton'
print(a) #Hello. Pyhton
print(a + ' :)') #Hello. Pyhton :)
print(type(a)) #<class 'str'>다음과 같이 변수에 문자열에 대한 데이터를 저장할 수 있음을 확인할 수 있으며 + 를 사용해서 문자열에 문자열을 붙일 수도 있다는 점을 알 수 있다. 또한 type()을 사용하면 str임을 확인할 수 있다.
print(1 == 2) # False
print(2 == 2) # True
print('' == 'null') # False다음과 같이 비교 연산자를 통해서 참과 거짓을 확인할 수 있다. 비교 연산자는 자바에서 올렸던 연산자를 참고하면 좋다.
[JAVA] 연산자
안녕하세요. 이번 글은 연산자에 대한 글입니다. - 연산자란? 연산자는 우리가 배웠던 수학처럼 값을 상황에 알맞게 계산하기 위한 예약어를 의미한다. 자료형 연산 기호 우선 순위 증감 연산자
untitedblue.tistory.com
- 여러 개의 자료를 한 곳으로! 딕셔너리, 리스트
- 딕셔너리 : 사전이라는 뜻에서 가져왔으며 Key와 Value값으로 구성되어 있는 자료형
- 리스트 : 목록이라는 뜻에서 가져왔으며 요소를 하나의 공간에 저장할 수 있는 자료형
파이썬에서의 리스트는 다른 언어와 다르게 하나의 리스트 안에 여러 형식의 자료형을 넣을 수 있다.
a = []
b = [1, 2, 3, 4, 5]
c = [1, "Hi", 2, "Python", 3.5]
print(a) # []
print(b) # [1, 2, 3, 4, 5]
print(c) # [1, 'Hi', 2, 'Python', 3.5]
print(b[0] + c[2]) # 3다음과 같이 리스트를 만들 수 있는 점을 시작으로 내부에 여러 데이터를 삽입할 수 있으며 다른 형태의 자료형도 함께 넣을 수 있다는 점을 확인할 수 있다. 또한 변수 오른쪽에 인덱스값을 지정함으로써 리스트 내부의 값들 중 일부만 발췌해서 가져올 수 있다는 점도 확인할 수 있다. 타입은 <class 'list'>이다. 추가로 같은 타입의 자료형이면 + 같은 연산자를 사용해서 문자열의 경우 값을 이어붙일 수 있고 숫자형의 경우 계산식처럼 활용가능함을 확인할 수 있다.
a = [1, 2, 3, 4, 5, ["Hello.", " Python"]]
print(a) # [1, 2, 3, 4, 5, ['Hello.', ' Python']]
print(a[-1]) # ['Hello.', ' Python']
print(a[5]) # ['Hello.', ' Python']
print(a[-1][1]) # Python조금 더 응용해보면 리스트 안에 리스트를 넣을 수도 있다. 이때 인덱스값을 -1로 해서 출력해보면 내부 리스트 전체가 출력됨을 확인할 수 있다. 물론 -1은 리스트에서 맨 마지막에 있는 값을 출력할 때 사용된다. a[-1][1]처럼 내부 안에 있는 리스트 안에서 상세 인덱스값을 추가적으로 선언함으로써 내부 리스트의 특정값을 가져와서 출력할 수도 있다. 인덱스값의 시작은 1이 아닌 0부터 시작한다.
a = [1, 2, 3, 4, 5, ["Hello.", " Python"], 10]
b = 'Python'
print(a[0:2]) # 0, 1
print(a[3:]) # 3, 4, 5, 6
print(b[0:2] + b[2:]) # Python
print(b * 3) # PythonPythonPython인덱스값을 넣는 괄호 안에 시작값 : 끝값을 설정함으로써 범위를 지정하는 방식으로 일부 데이터를 추출할 수도 있다. 이를 슬라이싱이라고 한다. 예를 들어 0:2라고 하면 0, 1번째 문자를 가져온다는 뜻이다. 다른 말로 하면 0번째부터 2번째 이전 값까지 가져온다는 뜻으로도 해석할 수 있다. 또한 시작값: 처럼 끝의 범위를 별도로 지정하지 않으면 끝까지 출력한다는 뜻으로 해석된다. 또한 상단의 코드처럼 문자열 또한 배열이자 문자의 집합체이기 때문에 슬라이싱할 수 있다.
추가로 * 연산자 뒤에 숫자를 입력하면 리스트 내지 문자열을 숫자만큼 반복 출력할 수 있다.
a = [1, 2, 3, 4, 5, ["Hello.", " Python"], 10]
print(a) # [1, 2, 3, 4, 5, ['Hello.', ' Python'], 10]
a[0] = 'p'
print(a) # ['p', 2, 3, 4, 5, ['Hello.', ' Python'], 10]
del a[0]
print(a) # [2, 3, 4, 5, ['Hello.', ' Python'], 10]
del a[0:2]
print(a) # [4, 5, ['Hello.', ' Python'], 10]
a.append(1)
print(a) # [4, 5, ['Hello.', ' Python'], 10, 1]
b = [1, 10, 0, 6, 5, 4, 7, 8, 9]
b.sort()
print(b) # [0, 1, 4, 5, 6, 7, 8, 9, 10]
b.reverse()
print(b) # [10, 9, 8, 7, 6, 5, 4, 1, 0]
#print(b.index(3)) #3 is not in list
print(b.index(9)) # 1
b.insert(7, 3)
b.insert(8, 2)
print(b) # [10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
b.remove(0)
print(b) # [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
print(b.pop()) # 1
print(b.count(5)) # 1
b.extend([20, 30])
print(b) # [10, 9, 8, 7, 6, 5, 4, 3, 2, 20, 30]- .len() : 리스트 내부 총 갯수
- .sort() : 오름차순 정렬
- .reverse() : 역순 정렬
- .pop() : 리스트 내 맨 마지막값 가져오기
- .insert([인덱스 위치값], [추가할 값]) : 원하는 위치에 데이터 추가
- .remove([제거할 값]) : 리스트에서 제거할 값을 찾아 데이터 제거
- .append([추가할 값]) : 리스트의 맨 끝에 데이터 추가
- .count([몇 개인지 찾고자 하는 데이터]) : 갯수를 알고자 하는 데이터의 갯수
- .extend([확장할 리스트]) : 리스트에 리스트를 추가하는 방식의 리스트 확장
- del [시작인덱스값 : 종료인덱스값] : 시작값부터 종료값 이전까지의 데이터 삭제
다음과 같이 리스트를 다양한 메서드를 통해 리스트 내 데이터 CRUD 작업을 진행할 수 있다. 여담으로 파이썬에서 정렬 관련 메서드가 기본 제공됨을 통해 파이썬이라는 프로그래밍 언어가 상당히 매력적임을 느낄 수 있다.
a = {1 : 'Python', 2 : 'Java', 3 : 'C#', 4 : 'Haskell', 5 : 'C++'}
print(a) # {1: 'Python', 2: 'Java', 3: 'C#', 4: 'Haskell', 5: 'C++'}
print(a[2]) # JAVA
a[6] = 'C' # Key값이 존재하지 않으면 새로 추가할 수 있다.
print(a) # {1: 'Python', 2: 'Java', 3: 'C#', 4: 'Haskell', 5: 'C++', 6: 'C'}
a[2] = 'JAVA' # Key값이 존재하면 value값을 변경할 수 있다.
print(a) # {1: 'Python', 2: 'JAVA', 3: 'C#', 4: 'Haskell', 5: 'C++', 6: 'C'}
del a[4] # del를 통해 특정 값을 삭제할 수 있다.
print(a) # {1: 'Python', 2: 'JAVA', 3: 'C#', 5: 'C++', 6: 'C'}다음으로 살펴볼 자료형은 딕셔너리이다. 특징은 키값의 중복이 허용되지 않으며 Key와 Value 값은 일대일 대응으로 무조건 둘이 같이 한 쌍으로 있어야 한다. 키값이 메인이며 이를 활용해서 Value값을 추출할 수 있다.
a = {1 : 'Python', 2 : 'Java', 3 : 'C#', 4 : 'Haskell', 5 : 'C++'}
print(a) # {1: 'Python', 2: 'Java', 3: 'C#', 4: 'Haskell', 5: 'C++'}
print(a.keys()) # dict_keys([1, 2, 3, 4, 5])
print(a.values()) # dict_values(['Python', 'Java', 'C#', 'Haskell', 'C++'])
print(a.items()) # dict_items([(1, 'Python'), (2, 'Java'), (3, 'C#'), (4, 'Haskell'), (5, 'C++')])
print(a.get(2)) # Java
print(a.get(0)) # None
print(1 in a) # True
print(0 in a) # False
a.clear()
print(a) # {}- .keys() : 딕셔너리에서 키값만 추출
- .values() : 딕셔너리에서 value값만 추출
- .items() : 딕셔너리에서 (Key, Value) 형식으로 한 쌍으로 묶어서 출력
- .get([키값]) : 키값을 토대로 Value값 추출
- [키값] in [딕셔너리 변수명] : 딕셔너리 안에 키값이 존재하는지 반환
- .clear() : 딕셔너리 내부의 값 모두 삭제
- 리스트와 같은 듯 다른 튜플 (Tuple)
- []로 둘러싸인 리스트와 다르게 ()로 둘러싸여있다.
- 리스트와 다르게 튜플 내 값에 대한 수정, 삭제, 생성 작업 불가능
- 슬라이싱, 인덱싱 가능
- 문자열을 리스트로 전환해주는 집합 (set)
a = set('Python')
b = set('Hello')
print(a) # {'P', 't', 'o', 'h', 'y', 'n'}
print(b) # {'H', 'e', 'l', 'o'}
print(set('apple')) # {'a', 'e', 'p', 'l'}다음과 같이 집합은 중복을 허용하지 않으며 순서가 없으며 정렬 방식은 오름차순이다. set()을 통해 문자열을 리스트로 변환할 수 있다.
c = {1, 2, 3, 4, 5}
d = {5, 6, 7, 8, 9}
print(c & d) # {5}
print(c | d) # {1, 2, 3, 4, 5, 6, 7, 8, 9}
print(c - d) # {1, 2, 3, 4}
print(d - c) # {8, 9, 6, 7}- & : 교집합
- | : 합집합
- - : 차집합
c = {1, 2, 3, 4, 5}
c.add(6)
print(c) # {1, 2, 3, 4, 5, 6}
c.add(1)
print(c) # {1, 2, 3, 4, 5, 6}
c.update({5, 7, 8, 9})
print(c) # {1, 2, 3, 4, 5, 6, 7, 8, 9}
c.remove(5)
print(c) # {1, 2, 3, 4, 6, 7, 8, 9}- .add([추가하고자 하는 값]) : 집합에 값 추가
- .update([업데이트 대상 집합]) : 집합에 집합 붙이기
- .remove([제거 대상 값]) : 집합에서 값 제거
'Programming Language > Python' 카테고리의 다른 글
| [Python] 외부 라이브러리 (0) | 2024.03.04 |
|---|---|
| [Python] 라이브러리 (0) | 2024.03.02 |
| [Python] 파이썬에서의 객체지향 - 클래스, 모듈, 내장함수, 패키지, 예외 처리 (1) | 2024.02.09 |
| [Python] 프로그래밍의 입출력, 함수 (0) | 2023.12.25 |
| [Python] 상황에 따라 제어하다. 제어문 (1) | 2023.12.23 |



